
Introduction
The AI community has been buzzing with the recent release of Llama3, the most powerful open-source LLM (Large Language Model) to date. One of the most common questions that enthusiasts and developers have is whether it’s possible to run Llama3 70B on a local machine with just a 4GB GPU. The answer is a resounding yes, thanks to the flexibility and efficiency of the AirLLM framework.
Running Llama3 70B Locally: Step-by-Step Instructions
Running Llama3 70B on a single GPU with just 4GB of VRAM might seem daunting, but with AirLLM, it’s surprisingly straightforward. Here’s how you can do it:
- Install AirLLM:
Begin by installing the AirLLM package using pip:
pip install airllm- Load and Run the Model:
With just a few lines of Python code, you can load the Llama3 70B model and start generating text:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("v2ray/Llama-3-70B")
input_text = ['What is the capital of the United States?']
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False)
generation_output = model.generate(input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)This setup allows you to run Llama3 on a machine with just 4GB of GPU memory, making it accessible even for those without high-end hardware.
Comparing Llama3 70B with GPT-4
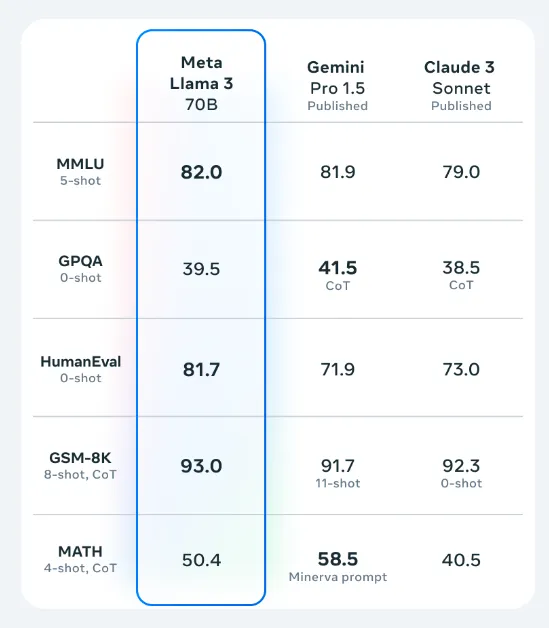
The performance of Llama3 70B is incredibly close to that of GPT-4, as reflected in the latest LMSys leaderboard. While it’s essential to note that comparing the similarly sized 400B model with GPT-4 and Claude3 Opus might be more appropriate, Llama3 70B holds its ground remarkably well.
Key Technological Advancements in Llama3
Llama3’s architecture remains consistent with its predecessors, but there are notable improvements in training methods. One of the key advancements is the adoption of DPO (Data Processing Optimization), a standard technique now employed by all top-ranking large models.
However, the real breakthrough comes from the massive increase in both the quantity and quality of training data. Llama3’s training data increased from Llama2’s 2T to a staggering 15T, thanks to rigorous data filtering and deduplication processes.
The Future of Open-Source LLMs
Llama3’s success raises an important question: Are open-source models beginning to surpass their closed-source counterparts? While it’s too early to declare a winner, the battle between open and closed-source AI models is far from over. The development of large models has become a game of burning cash, with only the most resourceful players likely to survive in the long run.
Conclusion
Running Llama3 70B on a single 4GB GPU is not just possible but also efficient, thanks to AirLLM. As open-source models like Llama3 continue to push the boundaries of AI, the debate between open and closed-source development will only intensify. For now, Llama3 stands as a testament to the power of open collaboration in the AI community.
Stay tuned as we continue to explore the latest advancements in AI technology and share open-source projects with our community.